Mašīntulkošanu (MT) mēdz uzskatīt par datorlingvistikas apakšnozari, kas pēta metodes teksta tulkošanai ar datoru. Praktiskie pētījumi mašīntulkošanā tika sākti drīz pēc pirmo datoru parādīšanās kā viens no potenciāliem datora lietojuma virzieniem. Pirmās neveiksmes mašīntulkošanā sekmēja plašāku datorlingvistikas pētījumu sākšanu. To rezultāti savukārt tika izmantoti mašīntulkošanas tehnoloģiju pilnveidē. Mūsdienu mašīntulkošanas sistēmas izmanto neironu tīklu modeļus, kas nemitīgi tiek attīstīti un pilnveidoti. Mašīntulkošana ir ne tikai pētniecības virziens, bet arī plaši lietota tehnoloģija un veiksmīgs komercprodukts. Mašīntulkošanas sistēmas tulkojuma kvalitāte var būtiski atšķirties dažādiem valodu pāriem un jomām. Lai arī mašīntulkošana tiek plaši lietota, tomēr tā joprojām nav sasniegusi savu sākotnējo mērķi ‒ pilnībā automatizēt jebkāda veida tulkošanu.



mašīntulkošana
Saistītie šķirkļi

Runāta teksta mašīntulkošana, izmantojot telefona lietotni.

Satura rādītājs
Mašīntulkošana ir viena no senākajām datorlingvistikas pētījumu jomām. Pirmie pozitīvie rezultāti mašīntulkošanā, kam sekoja mašīntulkošanas lietojamības kritika, kļuva par impulsu dziļākai valodas izpētei ar datora palīdzību. Lai arī mūsdienu mašīntulkošanai ir liela praktiskā (komerciālā) nozīme, tā nav zaudējusi pētniecisko aktualitāti kā sarežģīts dabiskās valodas apstrādes uzdevums, kuram tiek veidotas arvien efektīvākas, piemērotākas un precīzākas neironu tīklu arhitektūras, kas ļauj arvien labāk modelēt cilvēka tulkojumu.
Mašīntulkošanai mūsdienu pasaulē ir milzīga praktiskā nozīme, it īpaši Eiropas Savienībā (European Union), kur vienlaikus ar atbalstu daudzvalodībai jānodrošina tulkošana starp visām Eiropas Savienības valodām, tādējādi mazinot valodas barjeru. Mūsdienu mašīntulkošanas sistēmas izmanto gan publiskās pārvaldes iestādes, gan uzņēmumi, lai nodrošinātu daudzvalodu saturu. Mašīntulkošanu plaši izmanto lokalizācijas uzņēmumi. Tā iekļauta daudzos datorizētās tulkošanas rīkos (CAT-tools).
Vēsturiski mašīntulkošanas metodes tiek dalītas divās grupās: zināšanās jeb likumos balstītas metodes (tika plaši lietotas līdz 20. gs. beigām) un datos balstītās metodes (pirmie pētījumi 20. gs. 80. gadu vidū, turpinās mūsdienās).
Viens no veidiem, kā veidot mašīntulkošanas sistēmu, ir izmantot valodas likumus. Pats vienkāršākais veids ir likumi vārdu aizstāšanai avotvalodā ar vārdiem mērķvalodā. Šī metode parasti ir ļoti kļūdaina. Tāpēc parasti likumos (jeb valodas normās) balstītās sistēmas analizē ievadīto tekstu avotvalodā un izveido tā simbolisku reprezentāciju, no kuras tiek ģenerēts teksts mērķvalodā.
Likumos balstītas sistēmas pēc to abstrakcijas līmeņa tiek dalītas transfēra un interlingvas sistēmās. Transfēra sistēmās katram valodu pārim tiek izstrādāts savs valodas tulkojuma komponents (transfērs), kas avotvalodas struktūras pārveido mērķvalodas struktūrās. Transfēra komponentu veido divvalodu (parasti vienvirziena) transfēra vārdnīca un transfēra gramatika. Interlingvas mašīntulkošanas sistēmas izmanto starpniekvalodu (tā var būt kāda dabiskā vai mākslīgā valoda, valodas un simbolu apvienojums, vai vienkāršota angļu valoda), kura ideālā gadījumā ir valodneatkarīga.
Lai šīs metodes varētu veiksmīgi izmantot, nepieciešami plaši leksikoni ar morfoloģijas, sintakses un semantikas informāciju, kā arī pieredzējušu lingvistu rūpīgi izveidots apjomīgs gramatikas likumu apkopojums. Tas ir ļoti ilgstošs un dārgs process.
Līdz ar apjomīgu paralēlo tekstu korpusu uzkrāšanu likumos balstītas metodes nomaina datos balstītas metodes – sākumā piemēros balstīta mašīntulkošana un statistiskā mašīntulkošana (SMT), mūsdienās – neironu mašīntulkošana (NMT). Atšķirībā no likumos balstītām metodēm, šie risinājumi neizmanto morfoloģijas, sintakses un semantikas likumus, bet lielus paralēlos korpusus. Datos balstītas mašīntulkošanas priekšrocība ir tā, ka tajā jāiegulda mazāk cilvēkresursu un tā labāk pielāgojas dažādām valodas īpatnībām, ko varētu ignorēt valodas likumos balstītas sistēmas.
Statistiskās mašīntulkošanas sistēmas veido trīs komponenti: tulkošanas modelis, valodas modelis un dekodētājs. Tulkošanas modelis ir datora veidota vārdnīca, kuru dators “iemācās” no paralēlo tekstu korpusiem. Šādu vārdnīcu veido vārds vai vārdu virkne avotvalodā un tam atbilstošais vārds vai vārdu virkne mērķvalodā, kā arī šim pārim atbilstošo sastatījumu ticamība (varbūtība). Valodas modelī tiek apkopota vārdu un vārdu virkņu biežuma statistika, kas iegūta no mērķvalodas tekstu korpusiem. Parasti valodas modeļos iekļauj trīs līdz piecu (reizēm septiņu) vārdu virknes. Garākas vārdu virknes parasti valodas modelī neiekļauj, jo to biežums nav statistiski nozīmīgs. Gan tulkošanas modeli, gan valodas modeli dators automātiski izgūst no tekstiem. Tādējādi modeļos iekļautās vārdu virknes ne vienmēr atbilst vārdkopām vai bilingvālas vārdnīcas šķirklim. Statistiskā mašīntulkošanas sistēmā tulkošanas modeļa uzdevums ir ar statistisko līdzekļu palīdzību atspoguļot vārda, vārdu virknes tulkojuma iespējamību, savukārt valodas modeļa uzdevums ir atspoguļot vārdu secības ticamību un nodrošināt pareizā tulkojuma izvēli kontekstā. Dekodētāja uzdevums ir atrast statistiski labāko tulkojumu starp visiem iespējamajiem tulkojumiem, izmantojot tulkošanas modelī un valodas modelī apkopoto informāciju.
Pašlaik mašīntulkošanā dominē neironu tīklu modeļi, kas tulkošanu modelē ar mākslīgo neironu tīklu palīdzību. Atšķirībā no statistiskās mašīntulkošanas, kur tulkojuma modelēšanā iesaistīti vairāki komponenti, neironu mašīntulkošanā parasti ir tikai viens virknes pret virkni modelis, kas prognozē vārda tulkojumu, ņemot vērā avotvalodas teikumu un jau pārtulkoto teikuma fragmentu mērķvalodā. Vispirms teikums avotvalodā ar neironu tīkla palīdzību tiek kodēts par vektoru, pēc tam dekodētāja neirona tīkls prognozē vektoram atbilstošāko tulkojumu. Pirmajiem neironu tīklu modeļiem grūtības sagādāja garu teikumu tulkošana, tāpēc tika ieviests uzmanības mehānisms, kas dekodējot izmanto tikai daļu avotvalodas teikuma. Neironu mašīntulkošana uzrāda labus rezultātus valodu pāriem un jomām, kurām uzkrāti liela apjoma valodas dati. Tā kā neironu tīklu modeļi mašīntulkošanā tiek aktīvi pētīti, to arhitektūra nepārtraukti mainās un attīstās.
Pirmās idejas par mehānisku vārdnīcu izmantošanu valodas barjeru pārvarēšanai radās jau 17. gs. Tomēr tikai 20. gs. 30. gados šo ideju neatkarīgi patentēja franču izcelsmes armēņu zinātnieks Žoržs Artruni (George Artsrouni) un krievu zinātnieks Pjotrs Smirnovs-Trojanskis (Пётр Петрович Смирнов-Троянский).
Bieži par mašīntulkošanas (un datorlingvistikas) sākumu min amerikāņu zinātnieka Vorena Vīvera (Warren Weaver) 1949. gada memorandu, kurā viņš definē mašīntulkošanas uzdevumu, galvenās grūtības (piemēram, neviennozīmību) un iespējamos risinājumus – kriptogrāfiju, valodneatkarīgus (universālus) jēdzienus un citus. Drīz pēc tam mašīntulkošanas pētījumi tika sākti Vašingtonas Universitātē (University of Washington), Kalifornijas Universitātē Berklijā (University of California, Berkeley) un Masačūsetsas Tehnoloģiju institūtā (Massachusetts Institute of Technology). Viens no zināmākajiem tā laika sasniegumiem ir 1954. gadā veiktais Džordžtaunas eksperiments (sadarbība starp Džordžtaunas Universitāti (Georgetown University) Vašingtonā un IBM), kura laikā ar datoru tika pārtulkoti 49 rūpīgi izvēlēti teikumi no krievu valodas angļu valodā. Eksperimenta labie rezultāti radīja strauju mašīntulkošanas pētījumu uzplaukumu visā pasaulē. 1962. gadā 42 zinātniski pētnieciskie centri nodarbojās ar mašīntulkošanas sistēmu izstrādi. Šī laika posma (no 40. gadu beigām līdz 60. gadu vidum) mašīntulkošanas sistēmas mēdz saukt par tiešām jeb parindeņa mašīntulkošanas sistēmām, jo tās katru avotvalodas teikuma vārdu atrada vārdnīcā un aizstāja to ar tā tulkojumu mērķvalodā. Sarežģītākās parindeņu mašīntulkošanas sistēmas ietvēra arī ierobežotus morfoloģijas likumus, kas ļāva analizēt un sintezēt nepieciešamās vārda formas.
1966. gadā ASV tika izveidota speciāla Automatizētas valodas apstrādes konsultatīvā komisija (Automatic Language Processing Advisory Committee, ALPAC), kuras uzdevums bija novērtēt mašīntulkošanas devumu. Šīs komisijas ziņojumā mašīntulkošana tika novērtēta kā lēnāka, neprecīzāka un divreiz dārgāka, salīdzinot ar tulkotāju, un tika rekomendēts pievērsties fundamentāliem datorlingvistikas pētījumiem. Pēc ALPAC ziņojuma ASV valdība pārtrauca pētījumu finansēšanu mašīntulkošanas jomā. Padomju Sociālistisko Republiku Savienībā (PSRS) mašīntulkošanas pētījumi tika atsākti 1974. gadā. Tādējādi laika posms no 60. gadu vidus līdz 70. gadu vidum tiek vērtēts kā stagnācijas periods mašīntulkošanā, kad galvenā uzmanība tika pievērsta sintakses teorijām un valodas sapratnei. Tomēr mašīntulkošanas pētījumi netika pārtraukti Kanādā, Francijā un Vācijā. Šajā periodā tika izstrādātas arī vairākas pasaulē pazīstamas mašīntulkošanas sistēmas: Systran (ASV), ETAP-1 (PSRS), un citas. 1976. gadā Systran mašīntulkošanas risinājumu iegādājas Eiropas Komisija (European Commission) dokumentu tulkošanai, sākumā tulkošanai no franču valodas angļu valodā, vēlāk arī citiem valodu pāriem. Eiropas Komisija Systran izmantoja līdz 2010. gadam.
Jauns mašīntulkošanas uzplaukums bija vērojams laika posmā no 70. gadu vidus līdz 80. gadu beigām, kad sākās rūpniecisku mašīntulkošanas sistēmu izstrāde ‒ kā atbilde arvien pieaugošajam pieprasījumam pēc izmaksās efektīvām mašīntulkošanas sistēmām tehniskās un komerciālās dokumentācijas tulkošanai. Pētniecībā šī perioda galvenais virziens bija semantika. Taču gaidītie rezultāti netika sasniegti. Tā vietā parādījās interaktīvas un konkrētas nozares vajadzībām izstrādātas mašīntulkošanas sistēmas, piemēram, Monreālas Universitātes (Université de Montréal) TAUM-METEO sistēma, kas bija vienīgā pilnīgi automatizētā mašīntulkošanas sistēma Kanādas meteoroloģiskā tīkla prognožu tulkošanai no angļu valodas franču valodā. 70. gados Panamerikas Veselības organizācija (Pan American Health Organization) sekmīgi izstrādāja un plaši lietoja mašīntulkošanas sistēmu tulkošanai starp angļu un spāņu valodu.
80. gadu sākumā pieauga mašīntulkošanas sistēmu dažādība, palielinājās pētījumos iesaistīto valstu skaits, kā arī parādījās mašīntulkošanas sistēmu dalījums interlingvas un transfēra sistēmās. Mašīntulkošanas sistēmu izstrādē īpaša uzmanība tika pievērsta milzīgu leksikonu, terminoloģisko datu bāzu un zinību bāzu izveidei. Šajā laikā parādījās komerciālas lieldatoru sistēmas METAL, Logos, savukārt mikrodatoriem mašīntulkošanas risinājumus piedāvāja Globalink, Sharp, Mitsubishi un citas kompānijas. Tā laika nozīmīgākie projekti bija GETA-Ariane, SUSY, Mu, DLT, ROSETTA un divi starptautiski projekti ‒ EUROTRA, kura izstrādi atbalstīja Eiropas Komisija, un CICC (China International Capital Corporation Limited) projekts, kurā piedalījās Japāna, Ķīna, Indonēzija un Taizeme.
20. gs. 80. gadu vidus kļuva par pagrieziena punktu pārejai no likumos balstītām metodēm uz datos balstītām metodēm. 1984. gadā japāņu pētnieks Makoto Nagao (長尾 真) aprakstīja piemēros balstītas mašīntulkošanas modeli tulkošanai starp angļu un japāņu valodu. Modeļa pamatideja bija izmantot iepriekš pārtulkotas frāzes jeb analoģiju meklēšanu. 1991. gadā Pītera Brauna (Peter Brown) vadītā pētnieku grupa IBM nāca klajā ar mašīntulkošanas sistēmu Candide tulkošanai no franču valodas angļu valodā. Sistēma izmantoja statistiskās metodes, lai iemācītos tulkojumus no liela apjoma tekstu korpusiem. 1999. gadā Džona Hopkinsa Universitātes (John Hopkins University) darbsemināra dalībnieki implementēja vairumu no IBM modeļiem, padarot tos plaši pieejamus. Tos rīkkopā GIZA++ attīstīja Francs Jozefs Ohs (Franz Josef Och). Statistiskās mašīntulkošanas metodes kļuva populāras gadsimtu mijā. To sekmēja pieaugošā datoru jauda un datu glabāšanas apjoma pieaugums.
2002. gadā tika nodibināts pirmais statistiskās mašīntulkošanas uzņēmums Language Weawer. Statistiskās mašīntulkošanas sistēmas izstrādāja arī Google, Microsoft un IBM. Filips Kons (Philipp Koehn) ar kolēģiem izstrādā populāras rīkkopas statistiskās mašīntulkošanas sistēmu izveidei – Pharaoh (2004) un Moses (2007). Līdzīgi kā likumos balstītās sistēmas, statiskās mašīntulkošanas sistēmas sākumā izmantoja vārdu modeļus, bet vēlāk vārdu virknes (frāzes), sintakses un hierarhiskus frāžu modeļus, tika veidotas arī hibrīdas sistēmas. Viena no aktualitātēm bija automātiska mašīntulkošanas kvalitātes novērtēšana, kam 2001. gadā Kišore Papineni (Kishore Papineni) ar kolēģiem piedāvāja izmantot bilingvālās vērtēšanas metriku BLEU (bilingual evaluation understudy), kas, lai gan tiek kritizēta, vēl arvien tiek plaši lietota.
20. gs. beigās tika sākta arī runātās valodas mašīntulkošabas pētniecība (ATR, JANUS, TC-Star un Verbmobil projekti). Šajā laikā parādījās datorizētās tulkošanas rīki (Trados, SDL, Champollion u. c.), kas arvien plašāk tika lietoti programmatūras lokalizācijā. Gadsimtu mijā parādījās mašīntulkošanas risinājumi tīmeklī un mašīntulkošana sāka kļūt par masu produkciju.
Statistiskā mašīntulkošana bija dominējošā metode līdz 2016. gadam, kad to strauji nomainīja neironu mašīntulkošana. 1997. gadā Ramons Neko (Ramon Neco) un Mikels Forkada (Mikel Forcada) piedāvāja ideju par kodētāja-dekodētāja (encoder-decoder) lietojumu mašīntulkošanā, kas tā sarežģītības un nepietiekamo datora un valodas resursu dēļ tajā laikā neuzrādīja vērā ņemamus rezultātus. Tāpēc neironu tīklu modeļi vispirms tika izmantoti kā valodas modeļi statistiskās mašīntulkošanas sistēmās, bet vēlāk iekļauti statistiskās mašīntulkošanas sistēmās kā papildu vērtētāji tulkošanas modelim ‒ kā pārkārtošanas modelis, pirmskārtošanas modelis un citi.
Par mūsdienu neironu mašīntulkošanas pirmsākumu bieži uzskata 2013. gada Nala Kalhbrennera (Nal Kalchbrenner) un Fila Blansoma (Phil Blunsom) piedāvāto kodētāja-dekodētāja modeli, kas izmanto konvolūciju neironu tīklus avotvalodas teksta kodēšanai (attēlošanai) vektortelpā un rekurentos neironu tīklus dekodēšanai (tulkošanai) mērķvalodā. 2014. gadā Iļjas Sutskevera (Ilya Sutskever) vadītā pētnieku grupa piedāvāja izmantot daudzslāņu LSTM (long short-term memory ‒ garās īstermiņa atmiņas) neironu tīklu modeļus gan teikuma kodēšanai par fiksēta garuma vektoru, gan dekodēšanai, kas neironu mašīntulkošanas sistēmām ļauj labāk apstrādāt tālās atkarības un tulkot garākus teikumus. 2014. gadā Dmitrijs Bogdanovs (Дмитрий Степанович Богданов) ar kolēģiem iepazīstināja ar uzmanības mehānismu kā metodi, kas tulkojot ļauj izmantot konteksta būtiskāko daļu, tādējādi būtiski uzlabojot neironu mašīntulkošanas tulkojumu kvalitāti arī garākiem teikumiem. Pēc BPE (byte pair encoding – baitu pāru kodēšana) datu saspiešanas algoritma un attulkošanas idejas ieviešanas neironu mašīntulkošana kļuva par modernāko metodi. 2016. gada rudenī uzņēmums Google sāka statistiskās mašīntulkošanas sistēmu aizstāšanu ar neironu mašīntulkošanas sistēmām. 2017. gadā to sāka arī Facebook. Par pāreju uz neironu mašīntulkošanu paziņoja arī Amazon, Microsoft, Systran, IBM, Baidu un daudzi citi.
Pašlaik mašīntulkošanā dominē neironu tīklu modeļi, kas spēj ģenerēt plūstošāku tulkojumu nekā iepriekš lietotās metodes. Tā kā neironu mašīntulkošana ir salīdzinoši jauns pētījumu virziens, tas strauji attīstās, katru gadu tulkošanai piedāvājot arvien efektīvākus algoritmus. Pašlaik labākos rezultātus uzrādījusi Transformer modeļu arhitektūra. Tomēr arī pašreizējo neironu mašīntulkošanas sistēmu tulkojumiem ir nepieciešama pēcrediģēšana. Starp būtiskākajiem problēmjautājumiem neironu mašīntulkošanā ir datu kvalitāte un to trūkums jomai pielāgotas mašīntulkošanas sistēmas izveidei (vai tekstu apjomā nabadzīgam valodu pārim), nosaukto entitāšu, terminoloģijas un vairākvārdu savienojumu tulkošana, kontekstuāli korekta dokumentu līmeņa tulkošana. Aktuāla ir arī runātās valodas tulkošana. Mašīntulkošanas pētniecības rezultātu lietojamības izvērtēšanai Mašīntulkošanas darbsemināra (Workshop on Statistical Machine Translation, WMT; kopš 2016. gada – Conference on Machine Translation) ietvaros tiek rīkotas sacensības (shared task), lai atrastu tā brīža labāko risinājumu. Trīs gadus pēc kārtas (2017; 2018; 2019) ziņu tulkošanas uzdevumā starp angļu valodu un Baltijas valstu valodām (latviešu, lietuviešu un igauņu) sabiedrība “Tilde” ir uzrādījusi dalītus labākos rezultātus.
Mašīntulkošanas pētījumi notiek visā pasaulē, nozīmīgi pētniecības centri ir Edinburgas Universitāte (University of Edinburgh), Džona Hopkinsa Universitāte, Stenforda Universitāte (Stanford University), Karnegi Melona Universitāte (Carnegie Mellon University), Dublinas pilsētas universitāte (Dublin city university), Prāgas Kārļa universitāte (Univerzita Karlova), Āhenes Reinas-Vestfāles Tehnoloģiskā augstskola (Aachen-Rheinisch-Westfälische Technische Hochschule Aachen, RWTH), Datorzinātņu laboratorija mehānikas un inženierzinātnēm (Laboratoire d’Informatique pour la Mécanique et les Sciences de l’Ingénieur, LIMSI) Francijā un citi. Pētījumi notiek arī Eiropas Komisijas Tulkošanas ģenerāldirektorātā un starptautiskos uzņēmumos: Google, Baidu, Microsoft, Facebook un citos.
Mašīntulkošana ir strauji augoša zinātņu nozare, tāpēc jaunākie pētījumi meklējami gan mašīntulkošanas, gan datorlingvistikas konferenču rakstu krājumos. Nozīmīgākie žurnāli: Computational Linguistics (kopš 1988. gada), Machine Translation (kopš 1986. gada) un citi.
Multivide

Runāta teksta mašīntulkošana, izmantojot telefona lietotni.

ASV senatore Petija Marija (Patty Murray) izmanto Skype un Microsoft automātiskās tulkošanas programmatūru tērzēšanai tiešsaistē ar vīrieti Ķīnā Microsoft Inovāciju un politikas centrā. Vašingtona, 10.06.2015.
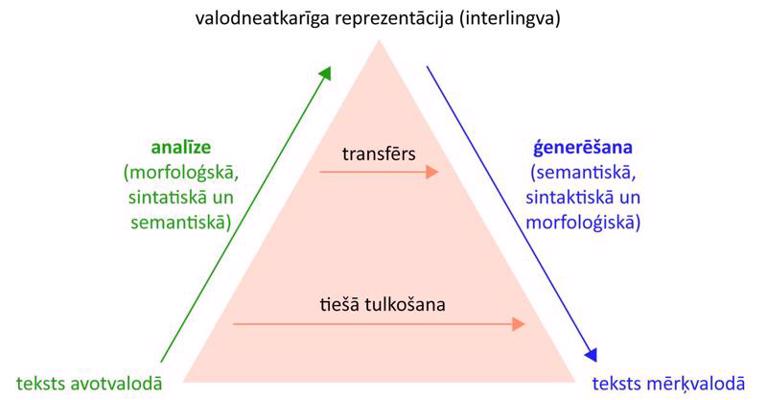
Vakvīza piramīda (Vauquois Pyramid).
Autora ieteiktie papildu resursi
Tīmekļa vietnes
Ieteicamā literatūra
Inguna Skadiņa "Mašīntulkošana". Nacionālā enciklopēdija. https://enciklopedija.lv/skirklis/-ma%C5%A1%C4%ABntulko%C5%A1ana (skatīts 28.05.2026)