Kopsavilkums
Lai apzīmētu līdzīga rakstura tekstu kopumu, piemēram, “latīņu dzejnieku korpuss”, “likumu korpuss”, termins “korpuss” fiksēts jau 18. gs. Savukārt ar nozīmi ‘lingvistiskai analīzei paredzēts teksta vai runas materiālu kopums’ termins “korpuss” lingvistiskajā literatūrā pirmo reizi lietots Viljama Sidnija Allena (William Sidney Allen) publikācijā periodiskajā izdevumā Transactions of the Philological Society 1956. gadā.

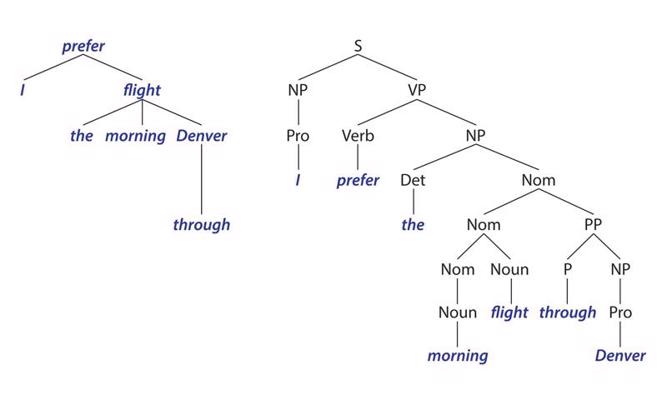
![1. attēls. Ar Stenforda Universitātes (Stanford University) vārdšķiru marķētāju (Part-of-Speech Tagger) marķēts teikums. [https://parts-of-speech.info/]](https://enciklopedija.lv/api/image/thumbnail?name=09da17fe210f-185d3dfd-18c0-4fcd-aee5-78a45c72edda.jpg&size=multimedia)